Metodología optimizada para la generación de indicadores utilizando Redatam
Área(s) de trabajo
Tema(s)
Resumen
Definir un indicador, desde la concepción teórica, es un proceso lógico no tan complicado pero sí de suma importancia, pues de ello depende no solo el dato final, sino la interpretación que se dará del él. Un indicador no puede tener más de una interpretación. Está conectado a un objetivo, a una meta, a una dimensión determinada, que son definidas por las variables que están involucradas y que hacen único el dato generado. Se debe tener bien delimitado el objetivo del indicador para así determinar un nombre que no deje vacíos o malinterpretaciones, lo cual facilitará el método de cálculo.
Los indicadores de seguimiento son una herramienta muy útil para vigilar la planificación y evaluar su grado de cumplimiento tanto en desarrollo o políticas públicas. Una de las definiciones más utilizadas por diferentes organismos y autores es la que Bauer dio en 1966: “Los indicadores sociales (…) son estadísticas, serie estadística o cualquier forma de indicación que nos facilita estudiar dónde estamos y hacia dónde nos dirigimos con respecto a determinados objetivos y metas, así como evaluar programas específicos y determinar su impacto”[1]. Un sistema de indicadores resume la intervención de distintas variables en un mismo contexto, haciendo comparable el estado de una situación o de algún aspecto particular, en un momento y un espacio determinados, ya sea por país, por período o por algún parámetro común.
Definir un indicador, desde la concepción teórica, es un proceso lógico no tan complicado pero sí de suma importancia, pues de ello depende no solo el dato final, sino la interpretación que se dará del él. Un indicador no puede tener más de una interpretación. Está conectado a un objetivo, a una meta, a una dimensión determinada, que son definidas por las variables que están involucradas y que hacen único el dato generado. Se debe tener bien delimitado el objetivo del indicador para así determinar un nombre que no deje vacíos o malinterpretaciones, lo cual facilitará el método de cálculo.
En este documento queremos presentar una metodología optimizada para calcular indicadores sociodemográficos a nivel de DAM (División política Administrativa Mayor) desagregados por tramo etario, zona de residencia y sexo utilizando los censos de población y vivienda como fuente de información y el módulo Redatam7 Process como plataforma de procesamiento. Las nuevas funcionalidades de Redatam, tales como TABLOP, permiten reducir enormemente la programación de una sintaxis para la creación de indicadores con sus desagregaciones.
Proceso para crear un sistema de indicadores
El primer paso para la creación de un sistema de indicadores es definir la estructura temática que este sistema va a presentar en una página Web de manera conceptual. Luego se deben precisar cada uno de los indicadores que se quiere presentar en cada tema y definir la fuente, períodos, filtros y desagregaciones (sexo, zona, edad, educación, etc.) y la metodología de cálculo para cada uno.
Es necesario asignar un código a cada indicador, a cada categoría que se utilizará en los filtros, a los períodos y a las áreas geográficas, como se ilustra en la imagen N° 1.
Imagen 1. Ejemplo de codificación de las categorías a utilizar en la desagregación de los indicadores

Con esta información se procede a generar una base de datos de entrada que contenga el valor para cada indicador y a su vez para cada desagregación posible definida para ese indicador (explicitando cada desagregación posible a través de un código) como se ilustra en la imagen N° 2.
Imagen 2. Base de datos de entrada del Sistema de Indicadores
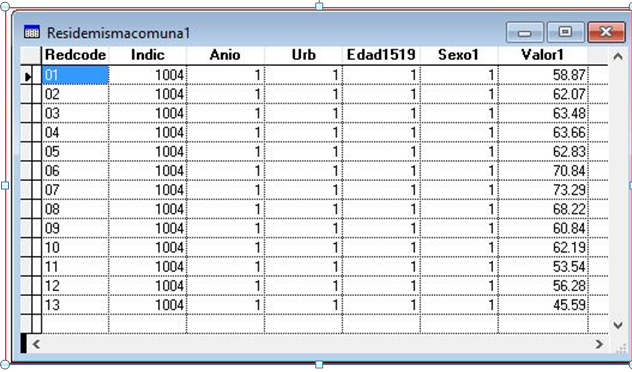
Para generar la base de datos de entrada es necesario procesar la fuente original de los datos, sea un censo de población o vivienda o una encuesta. En Redatam, tradicionalmente cada indicador se generaba siguiendo la lógica de calcular un numerador y un denominador y luego el porcentaje o la tasa según se definiera el indicador. Luego, se procedía a extraer este indicador con todas sus desagregaciones en una tabla de formato DBF o similar para conformar una sola tabla final. Ya que en Redatam no existe una plantilla universal, el output debe crearse definiendo cada columna con la variable que guarda ese valor, sea el valor de una desagregación o el del indicador mismo. Una vez definido el output, se comienza a estudiar cada variable involucrada.
Proceso tradicional en Redatam
Esto se puede demostrar en el siguiente ejemplo: el indicador “porcentaje de jóvenes que residen en la misma comuna en la cual nacieron” definido como el indicador “1004” calculado para Chile con el censo 2002. Se debe desagregar por región, por zona de residencia (urbano-rural), por sexo (hombre-mujer) y por tramo etario (15-19 años, 20-24 años y 25-29 años).
Actualmente, el valor asignado a las categorías de cada desagregación se almacena en variables temporales definidas con el comando DEFINE. Allí se ajusta cada una de las categorías según la definición previa para lograr una salida común. Para diferenciar las zonas de residencia en la tabla de salida se tienen que identificar tres variables, una para urbano con el valor 1, una para rural con el valor 2 y una para ambas zonas con el valor 3:
DEFINE REGION.URB
AS 1
TYPE INTEGER
DEFINE REGION.RUR
AS 2
TYPE INTEGER
DEFINE REGION.DOSZONAS
AS 3
TYPE INTEGER
Este procedimiento se debe repetir con las variables necesarias para generar el formato de salida requerido (zona de residencia, tramo etario, sexo, nivel educativo, etc.)
Por lo general, un sistema de indicadores se calcula a nivel de PAÍS, DAM o DAME. En Redatam, dada su estructura jerárquica, la geografía es el punto de partida para el cálculo de los numeradores y denominadores y allí donde se requiera el indicador para un total país, es necesario crear una variable
Se procede a crear el indicador con cada desagregación definiendo un numerador y un denominador y su relación porcentual. Siguiendo con el indicador 1004 esto tradicionalmente se calculaba así:
DEFINE REGION.NUM1
AS COUNT PERSONA
FOR AREA.ZONA=1 AND (PERSONA.EDAD>14 AND PERSONA.EDAD<20) AND PERSONA.SEXO=1 AND (PERSONA.NACIMIEN = COMUNA.COMUNA) TYPE INTEGER
DEFINE REGION.DENOM1
AS COUNT PERSONA
FOR AREA.ZONA=1 AND (PERSONA.EDAD>14 AND PERSONA.EDAD<20) AND PERSONA.SEXO=1 TYPE INTEGER
DEFINE REGION.VALOR1
AS (REGION.NUM1/REGION.DENOM1)*100 FOR REGION.DENOM1>0 TYPE REAL
Para cada indicador se debe definir una tabla de salida que debe seguir el esquema de la imagen N° 2. En Redatam, este tipo de tabla de salida se obtiene con una Lista por Área (AREALIST).
TABLE T1 AS AREALIST OF REGION,
REGION.INDIC, REGION.ANIO, REGION.URB, REGION.EDAD1519, REGION.SEXO1, REGION.NUM1, REGION.DENOM1, REGION.VALOR1
OUTPUTFILE DBF "D:\Bases\Chl2002\tablas\RESIDEMISMACOMUNA1.dbf" OVERWRITE
Tomando en cuenta que este indicador debe calcularse para tres opciones de zona de residencia (urbano, rural y ambas zonas), tres opciones de sexo (hombre, mujer y ambos sexos), cuatro tramos de edades (14-19, 20-24, 25-29 y total edad), se tiene un total de 36 combinatorias posibles, las cuales deben identificarse con 36 numeradores, 36 denominadores y por ende 36 relaciones porcentuales y 36 tablas de salida DBF, lo que hace la sintaxis para cada indicador extremadamente larga y tediosa, sin contar que después se deben pegar estos 36 archivos en uno solo para crear una tabla de entrada.
En resumen, esta metodología para crear indicadores en Redatam alarga la programación y el tiempo dedicado a cada indicador, y su extensión dependerá del número de opciones y filtros de las variables a cruzar.
Optimización del procesamiento de cada indicador
Dentro de las novedades y ajustes técnicos de Redatam7, se encuentra una forma más sencilla de generar indicadores, lo que permite resumir y acortar la serie de pasos previos para generar el indicador, así como reducir tiempo y esfuerzo.
Se trata establecer los indicadores a través de operaciones matriciales utilizando como input tablas de cruces y operadores matemáticos. Este nuevo comando se denomina TABOP. Este tipo de programación facilita la combinatoria de los filtros, generando una sola tabla como numerador y una sola tabla como denominador para cada indicador y si bien igual se debe recodificar y crear algunas variables temporales, como los grupos de edad o los niveles educativos, se reduce enormemente la creación de numeradores, denominadores y tablas de salida relacionadas a un solo indicador.
Siguiendo con el ejemplo anterior, se tiene en la base la variable región, zona de residencia y sexo, solo falta la variable edad joven, la que debe ser creada en una variable temporal para poder usarse como desagregación.
DEFINE PERSONA.EDADJOVEN
AS RECODE PERSONA.EDAD (15 : 19 = 1) (20 : 24 = 2) (25 : 29 = 3) ELSE 0
TYPE INTEGER RANGE (1 : 3)
VARLABEL "EDAD JOVEN" VALUELABELS 1 "15-19" 2 "20-24" 3 "25-29"
Luego se define una tabla como numerador en donde se cruzan las variables definidas como filtros (región, zona de residencia, sexo, edad, etc.) más el filtro que condiciona el indicador y luego una tabla como el denominador.
TABLE T1NUM AS FREQUENCY OF REGION.REGION BY AREA.ZONA BY PERSONA.EDADJOVEN BY PERSONA.SEXO
FILTER (PERSONA.NACIMIEN = COMUNA.COMUNA)
TABLE T1DEM AS FREQUENCY OF REGION.REGION BY AREA.ZONA BY PERSONA.EDADJOVEN BY PERSONA.SEXO
TABLE T1PORC AS TABOP OF (T1NUM / T1DEM) * 100 DECIMALS 2
A continuación se muestran las tablas utilizadas como numerador, denominador y la tabla final de la relación porcentual para la Región de Tarapacá con el censo de Chile 2002.
Tabla 1: Sección de la tabla utilizada como numerador T1NUM
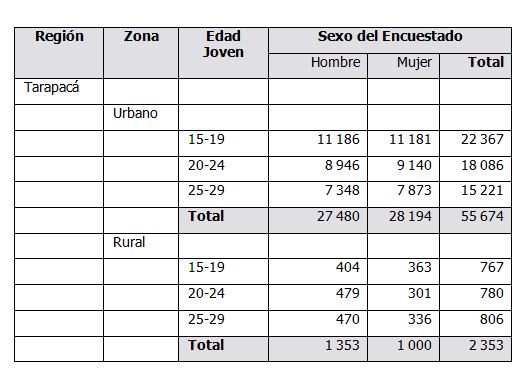
Tabla 2: Sección de la tabla utilizada como denominador T1DEM
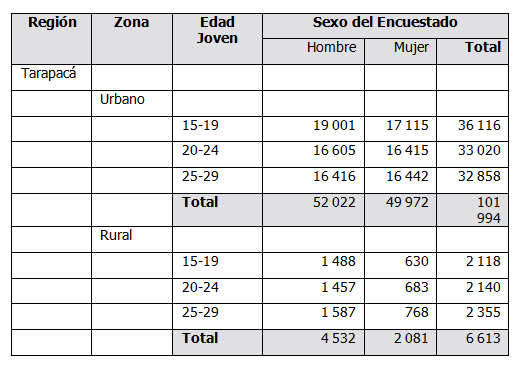
Tabla 3: Sección de la tabla final con la relación porcentual T1PORC
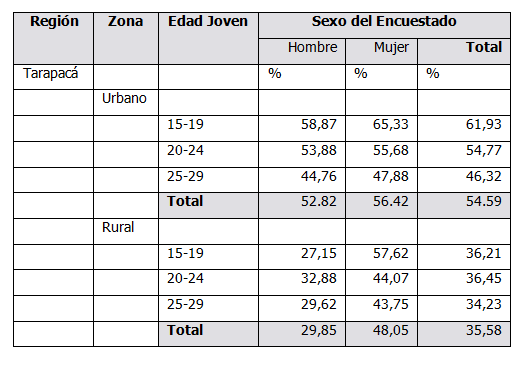
Tabla de salida SIDRA
A su vez se introduce un nuevo formato de salida denominado SIDRA, que genera archivos ASCII separados por coma con los resultados de una operación matricial además de los valores constantes que se desee agregar (como por ejemplo, los valores que no están incluidos en este indicador pero sí en filtros o valores que deben estar en la tabla final).
SIDRA, como formato de tabla de salida ASCII, viene con una serie de campos que permiten ser llenados por las variables relacionadas. El punto clave en este tipo de programación es que el orden de las dimensiones (variables) es exactamente el mismo orden que presentará la tabla de salida final, por tanto hay que ser metódicos a la hora de programar cada indicador. Es decir, las variables utilizadas para las tablas definidas como numerador y denominador deben ser consistentes en sus posiciones para todos los indicadores, así la tabla de salida será una sola y las variables mantendrán su posición en todos los indicadores. Por ejemplo, si al primer campo se asigna la región geográfica, el segundo para el sexo y así sucesivamente, para cada indicador que se cree se reservan esos campos de igual manera. Si para un indicador, no se utiliza un determinado filtro, se utilizan parámetros SIDRA para reemplazar el valor por uno genérico que equivale al no uso de ese filtro.
Los parámetros de SIDRA permiten utilizar los campos de acuerdo a un largo de valor y a una posición en la tabla de salida, por lo que se debe conocer el alcance de dicha tabla para optimizar su utilización y poder obtener la salida deseada. Como se observa en el cuadro Nº 1, existen diversas casillas que pueden ser ocupadas para obtener el output deseado, ya que tienen un largo que permite ingresar la codificación requerida. Asimismo, este formato permite la relación de hasta seis dimensiones (variables) en un cruce, por lo que facilita la programación.
Cuadro 1. Formato de salida SIDRA
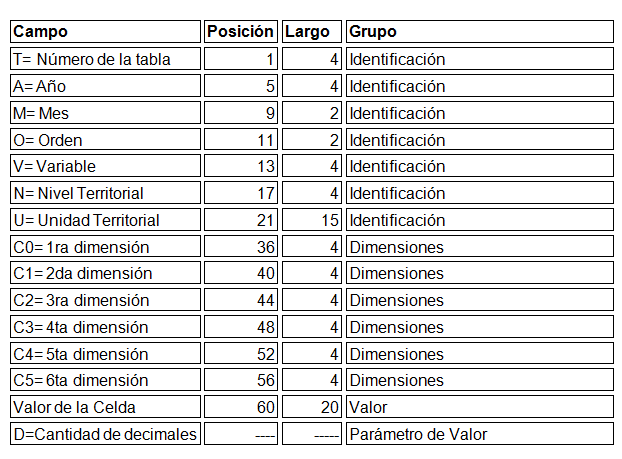
Por ejemplo, si tomamos el mismo indicador anterior, “porcentaje de jóvenes que residen en la misma comuna en la cual nacieron” la tabla final de salida después de TABOP se definiría de la siguiente manera:
OUTPUTFILE SIDRA "residemismacomuna.TXT" OVERWRITE
SIDRAPARM "A=2002 V=1004 C0=16 C1=3 C2=5 C3=3 D=2"
Imagen 3. Salida SIDRA archivo ASCII para el indicador 1004 y la región 06, censo de Chile 2002

Los primeros parámetros SIDRA que corresponde asignar y que no forman parte del cruce son el año y el número del indicador:
A= 4 dígitos para el año= 2002
V= código de 4 dígitos para el indicador=1004
En este formato de salida se resume también el cruce que permite obtener el valor total de las variables. Es decir, el NO uso de los filtros, para esto solo basta con establecer un valor de totales para las dimensiones involucradas utilizando los parámetros SIDRA. Como el orden de salida de los componentes estaría dado por el orden en el cruce que se definió para el numerador y denominador, en nuestro ejemplo, para REGION hay que definir el valor que toma total país (16), para ZONA hay que definir el valor para ambas zonas (3), para EDADJOVEN el valor sin edad (5), para SEXO el valor ambos sexos (3):
C0= 1ra dimensión del cruce, geografía =16
C1= 2da dimensión del cruce, zona =3
C2= 3ra dimensión del cruce, edad joven =5
C3= 4ta dimensión del cruce, sexo=3
También, hay que destacar que existen casos donde los indicadores requieren menos filtros que otros, por tanto en el cruce esas dimensiones no se evalúan; no obstante, como ya se aclaró, el formato SIDRA debe mantener el mismo orden de las dimensiones para la salida. En estos casos, existe el parámetro suplente S= que permite asignar un valor en la posición de la dimensión no evaluada, manteniendo el orden de la tabla de salida.
Continuando con el ejemplo, si un indicador no utiliza SEXO, habría que incluir un parámetro de la siguiente forma:
S3= 4ta dimensión del cruce, sexo =3
Así mismo, el parámetro D= es utilizado para asignar el número de decimales para el valor final del indicador
D= número de decimales =2
De esta manera, se resume el cálculo del indicador “porcentaje de jóvenes que residen en la misma comuna en la cual nacieron” en solo tres pasos: (1) definición de variables temporales para categorizar los filtros, como grupos etario joven; (2) la definición de un cruce de variables para el numerador y denominador; y (3) operar las tablas con TABOP y definir la tabla de salida en formato SIDRA con los parámetros recién explicados:
TABLE T1PORC AS TABOP OF (T1NUM / T1DEM) * 100 DECIMALS 2
OUTPUTFILE SIDRA "residemismacomuna.TXT" OVERWRITE
SIDRAPARM "A=2002 V=1004 C0=16 C1=3 C2=5 C3=3 D=2"
Como dato final, en Redatam y utilizando TABOP con el formato de salida SIDRA es posible acortar los pasos posteriores a la generación del indicador. Esto es, facilita la utilización de un mismo programa para definir y procesar de una sola vez una serie de indicadores para que sean almacenados en una misma tabla de salida. Esto, ya que se puede definir un solo archivo de salida TXT común para todos los indicadores agregando la función APPEND al lado del nombre del archivo de salida en cada nuevo indicador que se procese y al ejecutarse cada tabla irá agregándose al mismo archivo de salida.
Finalmente, con esta optimización en la programación de indicadores es posible resumir la cantidad de pasos en el procesamiento de cada uno. Como se mostró en el ejemplo anterior, el indicador requería 36 desagregaciones lo que involucraba definir 36 numeradores, denominadores y relaciones porcentuales con sus respectivas 36 tablas de salida individuales. Esta programación a través de operaciones matriciales, por el contrario, resume en tres los procesos contemplando todas las combinatorias de variables y filtros que requiere el indicador. Creemos que este es un gran avance en la generación de indicadores de diversa índole en el futuro.
[1] Horn, Robert V. (1993), Statistical indicators for the economic and social sciences, Cambridge University Press, pág. 147.