Open Census: Framework para extraer y procesar datos censales desde Redatam
Work area(s)
Topic(s)
Teaser
La importancia de disponer de información censal para el desarrollo de un país es muy alta. Por medio de ella podemos estimar, por ejemplo, no solo las necesidades de su población sino la distribución espacial de esas necesidades. Por ejemplo, la disponibilidad de viviendas, la estructura demográfica de los hogares, el poder adquisitivo de las familias, factores asociados a la segregación, etc. Acceder a información censal de manera sencilla y dinámica permite incluso abordar problemáticas complejas como es la influencia que ejercen recientes políticas tributarias sobre la estructura demográfica de un país y así refinar nuevas políticas y acciones que mejoren las condiciones de vida de los habitantes de un país. Es por ello que el correcto tratamiento de datos sociales, económicos y demográficos pareciera ser un paso fundamental en la evaluación y establecimiento de programas en materia de educación, empleo, vivienda y salud, entre otros.
La creciente necesidad de extender el uso y flexibilizar el acceso a datos censales ha generado importantes mejoras de las herramientas informáticas que describen el estado sociodemográfico de las naciones. Este incremento de nuevas herramientas es frecuentemente generada por necesidades particulares de proyectos que buscan dar valor agregado a datos censales. Redatam se ha posicionado como una de estas herramientas líderes en el procesamiento, análisis y difusión de datos y micro-datos provenientes de los censos de población y vivienda para la región de Latinoamérica como de otras regiones del mundo. Aquí presentamos Open Census, un marco de trabajo, o Framework, que facilita la extracción masiva de variables y posterior procesamiento desde una base de datos Redatam. Mostramos además aplicaciones directas de esta solución a proyectos de visualización y análisis de datos de diversas fuentes. Esperamos con esto contribuir y extender la creciente funcionalidad de Redatam7 para el análisis de información censal.
INTRODUCCIÓN
La importancia de disponer de información censal para el desarrollo de un país es muy alta. Por medio de ella podemos estimar, por ejemplo, no solo las necesidades de su población sino la distribución espacial de esas necesidades. Por ejemplo, la disponibilidad de viviendas, la estructura demográfica de los hogares, el poder adquisitivo de las familias, factores asociados a la segregación, etc. Acceder a información censal de manera sencilla y dinámica permite incluso abordar problemáticas complejas como es la influencia que ejercen recientes políticas tributarias sobre la estructura demográfica de un país y así refinar nuevas políticas y acciones que mejoren las condiciones de vida de los habitantes de un país. Es por ello que el correcto tratamiento de datos sociales, económicos y demográficos pareciera ser un paso fundamental en la evaluación y establecimiento de programas en materia de educación, empleo, vivienda y salud, entre otros.
De hecho, un mundo globalizado como el de hoy, definido por la libre circulación de información, dinero y personas, ha ido situando en el centro del debate social y político el análisis de datos empíricos que genera una sociedad. Esto ha tenido profundas consecuencias sociales y culturales, posiblemente asociadas a la homogeneización de los aspectos culturales y normativos que ha hecho que la valoración de los individuos obedezca a su simple razón de ser. Si aceptamos esto último, es posible concebir que cada ciudadano pueda contribuir en el análisis social, económico, demográfico sin mayores preámbulos. Sin embargo, la aceptación de este nuevo orden social exige liberar el acceso a esta información empírica, sin afectar la privacidad de la misma, manteniendo la anonimización de la información de personas, no solo para académicos e investigadores, sino para cualquier usuario, quien podrá, eventualmente, contribuir al diseño de políticas que mejoren el bienestar de su propia sociedad.
El proyecto Eigencities[1] tiene por objetivo desarrollar una plataforma disponible de información urbana. Trabajamos con fuentes de datos convencionales (Encuestas origen-destino, encuestas socio-económicas) y no-convencionales (Tweets, registros de llamadas y de datos móviles anónimos de telefonía) para desarrollar algoritmos que permitan observar las distintas dinámicas sociales y geográficas de las ciudades chilenas (ver descripción en www.ecoinformatica.cl). Es en el desarrollo de este proyecto que surge la necesidad de contar con aquellos microdatos censales abiertos, específicamente de Chile 2002, que el INE pone a disposición del público en formato Redatam.
Un análisis inicial de los datos sociodemográficos y económicos para Chile nos mostró el enorme potencial de Redatam. Sin embargo, los particulares requerimientos de nuestro proyecto exigen un acceso de forma abierta y masiva a los microdatos, en otro formato fuera de Redatam. Si bien el uso y análisis de los datos censales hoy es posible solo utilizando el programa Redatam, vía el procesamiento en línea que ofrece el INE[2], la máxima desagregación geográfica permitida es a nivel de la comuna, lo cual no permite análisis focalizados a escalas menores, al menos, desde su interfaz web. Buscando sobrellevar esta limitación y entendiendo que el censo si permite desagregar hasta niveles menores (manzanas, distrito, zonas), no así una encuesta, es que se desarrolló este framework presentado aquí para facilitar el acceso a dichos datos en forma abierta. Así, y con el ánimo de contribuir a facilitar el acceso a los microdatos censales, nace el proyecto que describimos a continuación, un marco de trabajo para el acceso abierto a microdatos censales desde una base de datos Redatam. Lo llamamos: Open Census.
La necesidad de contar con accesos flexibles a bases de datos y funcionalidades de Redatam no pareciera estar limitada a nuestro proyecto Eigencities, la aparición de otros proyectos con similares objetivos lo atestiguan. Estos han buscado interconectar otras plataformas de uso común con el backend ofrecido por Redatam (ver recuadro).

Solución propuesta
El framework propuesto permite extraer microdatos censales de forma masiva a un set de archivos *.csv usando la versión PC de Redatam y su módulo de consultas de Redatam Process. A su vez, crea un sencillo script para importar los archivos *.csv a una base de datos Sqlite3. Si bien nos encontramos aún en etapa de desarrollo, el software ha alcanzado cierta madurez que nos permite presentar la herramienta, perfeccionar su funcionamiento y adaptarla a los distintos usos. Open Census está escrito en Python 2.7.11 y se encuentra disponible en un repositorio GitHub[3] para su descarga, contribución y uso.
El módulo trabaja de forma stand-alone en un computador personal, para lo cual es necesario tener por un lado el programa Redatam7 instalado[4] y por otro lado contar con una base de datos (censos u otra fuente de datos) en formato Redatam en el mismo computador (diccionario *.dic o *.dicx, archivos de punteros .ptr y de varibales .rbf).
El uso del framework se especificará en cuatro pasos a seguir, como se muestra en el Diagrama 1.
Diagrama 1. Descripción del Framework
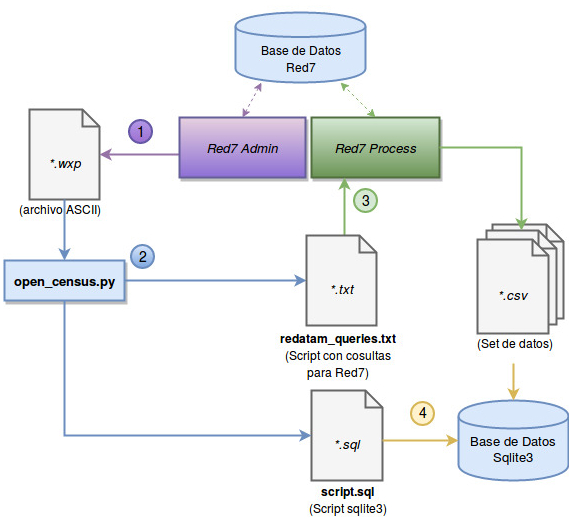
a Componentes del framework. La secuencia de acciones corresponden a: (1) Extracción de archivo *.wxp de la base de datos usando la aplicación Red7 Admin. (2) Uso de Open Census para la generación de archivo de consultas y script para importar datos a sqlite3. (3) Uso de archivo de consultas generado en Red7 Process. (4) Incorporación de set de datos extraídos en formato *.csv a una base de datos Sqlite3.
1. Extracción de archivo *.wxp usando Redatam7 Admin
Redatam7 Admin es el módulo de Redatam7 que provee una serie de herramientas para trabajar y manipular las bases de datos, por ejemplo, para cambiar las definiciones de algunas variables, convertir los diccionarios entre versiones, descargar bases de datos, etc. En esta sección, usamos una de las tantas utilidades de conversiones de archivos que ofrece: La conversión del diccionario, archivos *.dicx a formato ASCII, archivo *.wxp.
Para obtener el archivo *.wxp de una base Redatam debemos abrir la base de datos en Red7 Admin y, en el apartado “Conversiones”, hacer clic en “DicX to Wxp” y finalmente almacenarlo en disco con algún nombre. Esta conversión transformará un archivo *.dicx a *.wxp. Si no se cuenta con el archivo *.dicx pero si con uno *.dic (antiguo archivo de base Redatam), Red7 Admin también cuenta con una herramienta para transformar archivos *.dic a *.dicx. En este último caso, se debe hacer uso de esta operación.
El archivo *.wxp será el archivo que leerá open_census.py para generar el script de consultas Redatam y el script para importar datasets *.csv a Sqlite3.
2. Extracción de micro-datos con Open Census
El script python “open_census.py” usa el archivo *.wxp para generar todas las consultas posibles definidas en Redatam por área, pero sin ningún cálculo sobre ellas. Estas son almacenadas en un archivo de texto plano (*.txt). Esta serie de consultas, deben ser ejecutadas en Red7 Process para así obtener los microdatos para las diversas entidades (“Persona”, “Vivienda”, “Hogar”, etc.) y variables (“Nivel educacional”, “Cultura”, etc.) presentes a la base de datos.
Para hacer uso del script se debe escribir en el procesador de comandos de windows (cmd):
> python open_census.py --wxp_file [nombre_archivo.wxp] --csv_folder [ruta_carpeta_csv*] --level [nivel_geo*]
[nombre_archivo.wxp] corresponde al nombre del archivo de entrada en formato *.wxp exportado desde Redatam, [ruta_carpeta_csv*] es la carpeta donde queremos que Redatam exporte los archivos *.csv (Este parámetro es opcional. Por defecto se exportarán en el directorio raíz “C:/”. Si este último no se indica, puede omitirse el parámetro “--csv_folder”) y [nivel_geo*] que especifica el nivel geográfico del cual se obtendrán los datos censales. Este último parámetro también es opcional, por defecto la extracción del nivel “MANZENT” equivalente a “Manzana Censal”. Si el nivel no se indica, tampoco debe indicarse el parámetro “--level”.
Por ejemplo, si el archivo extraído de Redatam tiene el nombre “diccionario.wxp” y la carpeta a la cual se quiere exportar los archivos *.csv es “D:/data/” a un nivel geográfico de manzana censal “MANZENT”, se debe indicar en consola:
> python open_census.py --wxp_file diccionario.wxp --csv_folder D:/data/ --level MANZENT
Esto generará un archivo que se puede ejecutar como script con una serie de consultas descritas en lenguaje de consulta Red7 Process. Este script será guardado en formato de texto simple (*.txt) y podrá posteriormente ser usado para extraer la información requerida desde Redatam. Además, generará un archivo denominado “script.sql” con las instrucciones para importar los datos extraídos a una base de datos Sqlite3.
3. Uso de consultas Redatam generadas para extracción de datos
Una vez en Red7 Process (con la base de datos cargada) debemos hacer clic en “Home” > “New” > “Command Set”. Esto último desplegará una nueva ventana donde podemos hacer uso del lenguaje de consultas de Redatam.
Ahí debemos ingresar las consultas Redatam generadas de forma automática por Open Census y ejecutarlas. Los datos serán exportados en archivos *.csv y podrán ser visualizados o tratados en Excel, NeoOffice, Calc u otras hojas de cálculo. Para bases de datos con grandes volúmenes de información, esta sencilla herramienta es tremendamente útil, debido a que es posible agilizar el proceso de extracción de datos a una serie de archivos *.csv. Si bien la herramienta Red7 Process permite realizar extracción de datos por consulta, este módulo autoriza extraer la información por nivel en un solo evento.
Es importante indicar que las consultas se realizarán siempre y cuando el proveedor de la base de datos Redatam autorice el acceso a la información. Open Census solo extrae microdatos por medio de las herramientas que Red7 Process provee. Si la base de datos Redatam contiene restricciones de acceso a determinados niveles, variables o entidades, los microdatos no serán extraídos y Red7 indicará un error de acceso.
4. Incorporación de microdatos a base de datos Sqlite3
Sqlite3 es un sencillo pero potente motor de base de datos que permite tener una base de datos relacional SQL (Structured Query Language) en un solo archivo. Eso hace que su uso sea muy extensivo para proveer de soluciones ágiles. Si existe la necesidad de importar estos datos extraídos a una base de datos Sqlite3 para realizar consultas SQL, se puede hacer uso del script que OpenCensus genera automáticamente: “script.sql”.
Si se desea utilizar Sqlite3 directamente en procesador de comandos de windows “cmd”, basta con ejecutar Sqlite3 como sigue:
> sqlite3 [nombre_base_de_datos.db]
Finalmente, insertar las líneas generadas en “script.sql” para que comience a importar cada uno de los set de datos extraídos en pasos anteriores.
Ejemplo de uso de la base de datos Sqlite con microdatos censales de Chile
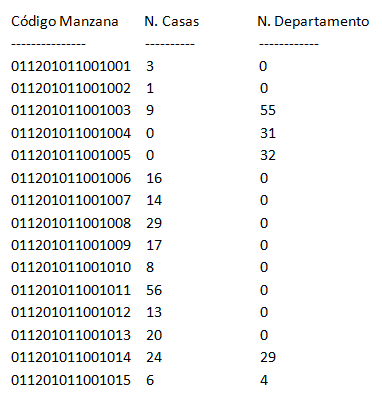
Una vez importado el script y el set de datos *.csv en Sqlite3, si se requiere conocer cuántas personas residen por manzana censal en “Casa” y cuántas en “Departamento”, además de su código de manzana censal, la consulta SQL asociada para obtener los primeros 15 registros corresponde a:
sqlite> SELECT REDCODE as "Código Manzana", F_1 as "N. Casas", F_2 as "N. Departamento" FROM VIVIENDA_TIPOVIV LIMIT 15;
En este caso particular, la tabla “VIVIENDA_TIPOVIV” contiene los valores, por manzana censal, del tipo de vivienda que contestaron las personas encuestadas en dicha manzana. El campo “F_1” corresponde a “Casa” y “F_2” corresponde a “Departamento”.
Al ejecutar esta consulta SQL en la consola de Sqlite3, se obtendrá un resultado como el que se presenta a continuación:
Aplicaciones
Una aplicación directa de Open Census es la posibilidad de generar consultas de microdatos censales para áreas geográficas variables. Normalmente, los indicadores suelen agruparse por ciudades, provincias o regiones. Sin embargo, estas áreas geográficas tienen una alta arbitrariedad, dado que los límites políticos no siempre coinciden con los límites reales. En el caso específico de las ciudades, la discusión en los últimos años se ha centrado en determinar cuáles son sus límites reales (si es que siquiera existen). Para esto, sería conveniente poder mover el límite político para así incluir nuevas zonas o descartar otras ya incluidas, y ver cómo varían los indicadores de estas “nuevas ciudades”. Esta es la propuesta del proyecto Eigencities (http://ecoinformatica.cl/proyecto/eigencities/), para el cual se han generado una serie de herramientas Web que permiten visualizar los datos censales de una manera dinámica. A continuación se detallan tres herramientas que se han generado en el marco de Eigencities, y que hacen uso de Open Census.
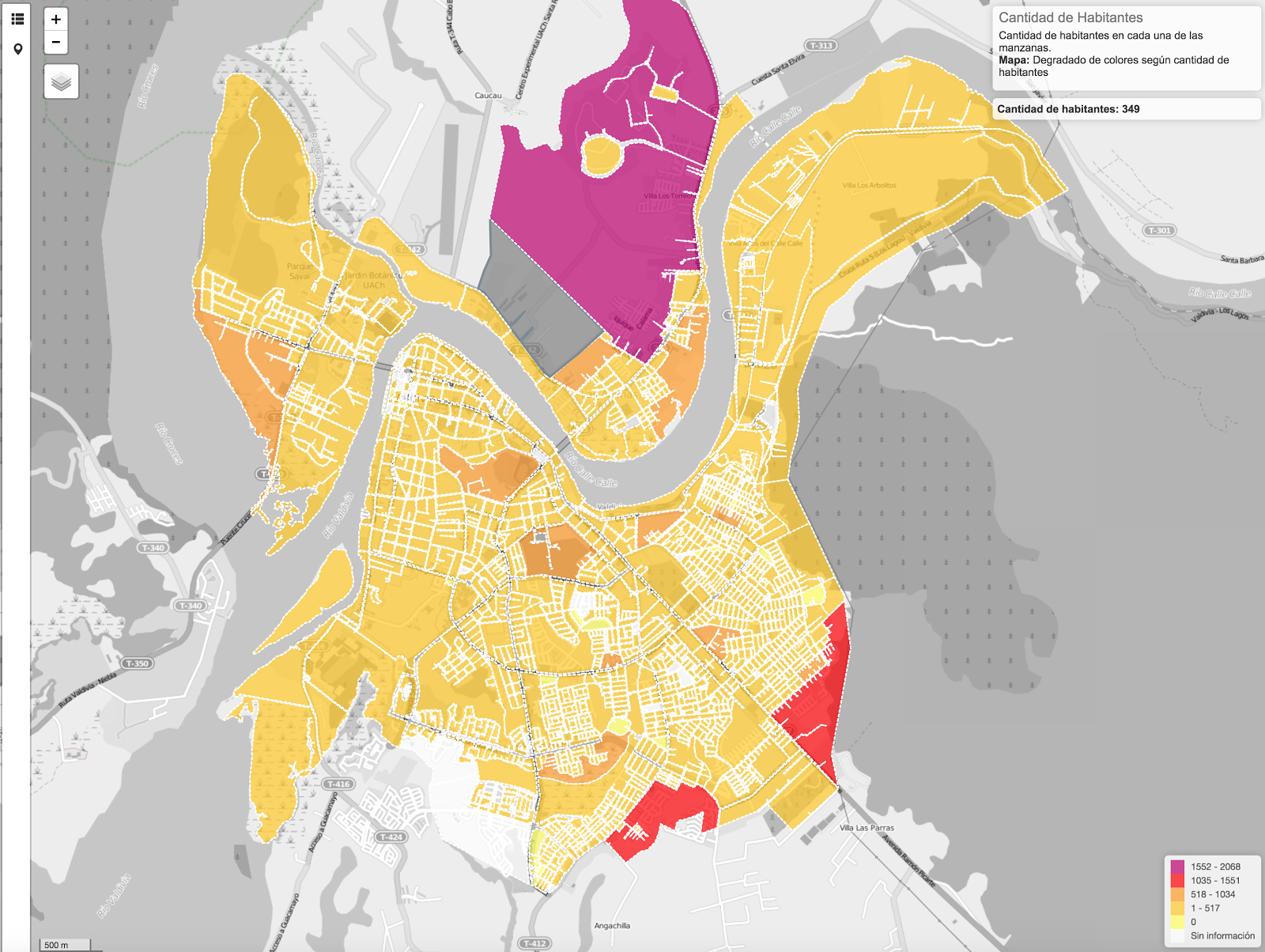
a) Visualizador de manzanas censales:
Esta herramienta hace uso directo de Open Census y simplemente extrae los datos censales para cada manzana censal y permite visualizarlos en un mapa dinámico, posibilitando elegir la variable a visualizar.
Imagen 1
Visualizador de manzanas censales
b) Delimitador de zonas urbanas
Como se detalló anteriormente, Eigencities se enfoca en analizar distintas definiciones de ciudad, moviendo sus límites y evaluando cómo cambian sus indicadores censales, como cantidad de población, vivienda, hogares, entre otros. Para esto, es necesario poder agrupar zonas de la ciudad, según distintos criterios. Como se muestra en la imagen 2, se le puede dar un valor de “centralidad” a cada zona, que indica qué tan “neurálgicos” son esos puntos (obtenido a través del análisis del movimiento de las personas, a partir de los datos de telefonía celular). Con estos valores, podemos fijar un “umbral”, de manera que solo las zonas que tengan valores de centralidad sobre ese umbral, pertenecerán a la ciudad. Luego, para cada valor de ese umbral habrá una ciudad distinta, y para cada una de estas ciudades se agruparán los datos censales correspondientes a esas zonas.
Imagen 2
Visualizador de Eigencities, para el caso de Santiago de Chile y sus alrededoresa
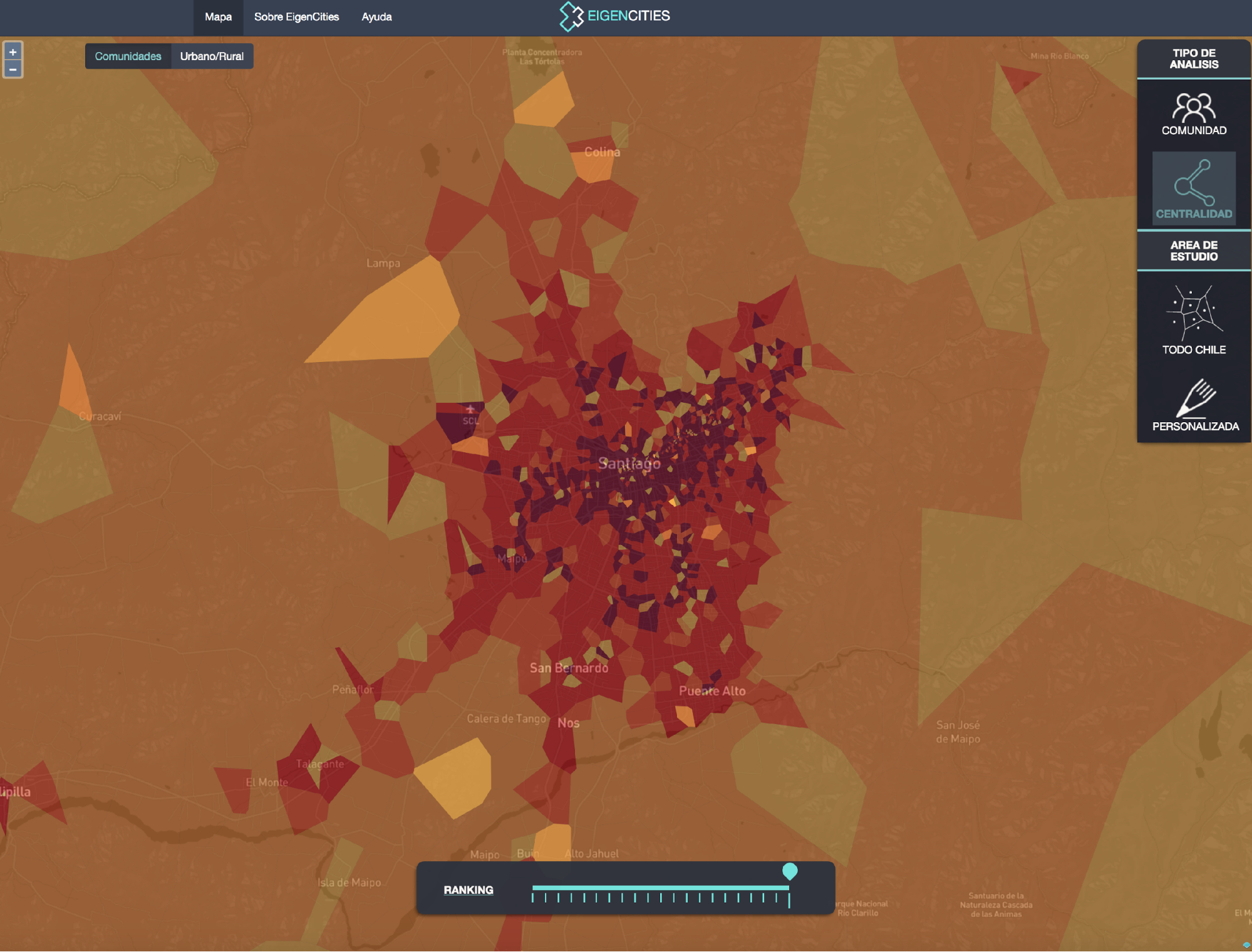
a Los colores oscuros representan zonas más neurálgicas o centrales de la ciudad. Para cierto umbral determinado (determinado por el deslizador “ranking” que se muestra abajo), solo las zonas con mayor centralidad que ese valor serán incluidas como parte de la ciudad.
c) Análisis de comunidades
Por último, podemos analizar el interior de la ciudad, y preguntarnos cómo se divide a partir del movimiento de la gente. Dada la alta segregación de las urbes, en especial en Latinoamérica, podemos pensar que la gente cuando se mueve dentro de la ciudad en realidad se mueve dentro de su “burbuja” o sub-zona. Esto se puede visualizar mediante el análisis de las trayectorias de la gente, en combinación con algoritmos estadísticos que explotan datos de la trayectoria individual extraídos del uso de telefonía móvil buscamos mostrar cómo se divide la ciudad internamente. El resultado se muestra en la imagen 3. Al igual que para el caso anterior, Open Census permite extraer los datos asociados a cada sub-zonas o comunidades, de manera de analizar los indicadores censales de estas áreas y evaluar diferencias entre ellos.
Imagen 3
Visualización de la segregación de Concepción y sus alrededoresa
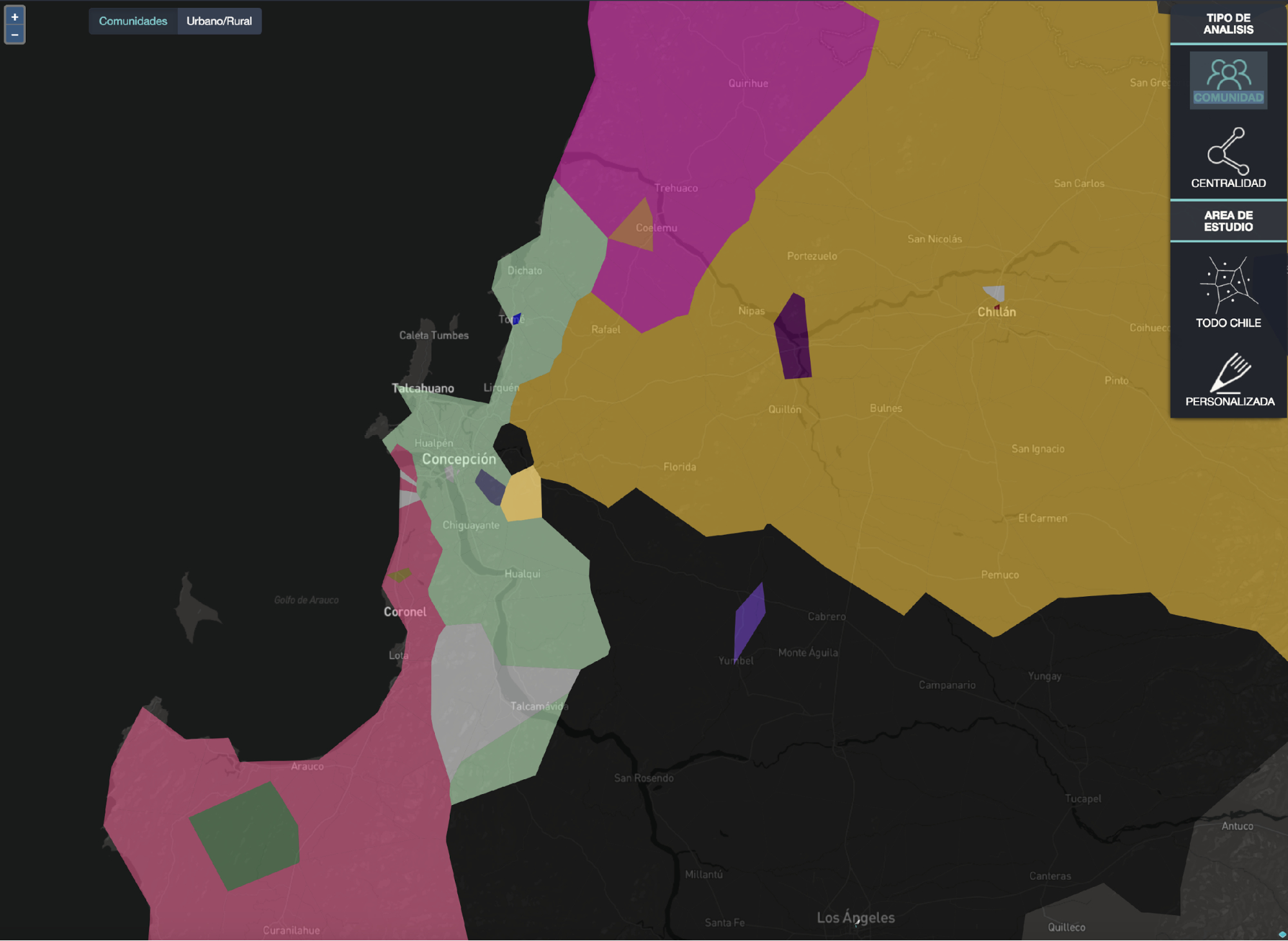
a Visualización generada a partir del movimiento de las personas. Cada color representa una comunidad o sub-zona. Estadísticamente, las personas suelen moverse dentro de estas sub-zonas significativamente más que entre una y otra.
Conclusiones
Si bien Redatam permite a usuarios trabajar y analizar de forma simple la información censal a través de su sintaxis o a través de procesamientos en línea, muchos requerimos exportar masivamente estos datos para cruzarlos con otra información y analizarlos en otras plataformas. El módulo Open Census requiere contar con la base de datos censal y esto solo será posible si el país a través de sus institutos nacionales de estadísticas sigue una política de transparencia y así lo prevén, como es el caso de Chile, el Uruguay y el Ecuador. La política seguida por cada país difiere a lo largo de Latinoamérica.
La solución propuesta aquí facilita este proceso y ofrece la posibilidad de presentarla en un formato de uso más universal como CSV, un formato muy utilizado dada sus prestaciones y sencillez de representación. La principal ventaja de extraer los datos a CSV radica en su simplicidad al momento crear y editar este tipo de documentos, ya que se puede abrir en cualquier editor de texto y ser manipulado en cualquier lenguaje de programación como Python, Java, Scala, etc. Además, este formato permite interoperar con otros gestores de bases de datos relacionales (tales como MySQL, PostgreSQL, SQLite, etc.) como no relacionales (tales como MongoDB, CouchDB, Redis, etc.).
La utilidad de exportar los archivos csv a una base de datos Sqlite propone una manera simple de interoperar con bases de datos relacionales locales. SQL ha sido por mucho tiempo un lenguaje de consulta esencial para datos complejos y existe un importante número de usuarios y desarrolladores que lo manejan.
Esperamos que este proyecto contribuya al acceso transparente de la información censal sin la necesidad de aprender nuevos lenguajes de consulta o depender de herramientas particulares.
Finalmente, en este artículo presentamos aplicaciones directas del framework desarrollado. Si bien nace como una necesidad específica del proyecto Eigencities, ayuda a agilizar el proceso de extracción y modelamiento de bases de datos para muchos tipos de proyectos que requieran usar microdatos censales de Redatam. Este es el caso de las aplicaciones web desarrolladas en nuestro proyecto, que permiten visualizar información censal, data-points de tweets y datos que provienen del análisis de registros CDR (Call Detail Records), entre otros. Esperamos contribuir y extender la creciente funcionalidad de Redatam7 tanto para cubrir requerimientos específicos como para apoyar proyectos científicos y tecnológicos enfocados en valorizar y dar sentido a datos censales.
|
Open Census es desarrollado como parte del Proyecto FONDEF IDeA ID15I10313 “Desarrollo de algoritmos de agrupamiento socio-espacial para develar dinámicas urbanas a partir de datos en tiempo cuasi-real no-convencionales en la planificación, gestión y monitoreo de la ciudad” adjudicado al Laboratorio de Ecoinformática de la Universidad Austral de Chile junto a la Universidad Católica, University College of London, la unidad de Ciudades Inteligentes del Ministerio de Transporte, el Centro I+D de Telefónica e INRIA Chile.
Open Census está escrito en Python 2.7.11 y se encuentra disponible en un repositorio Github (disponible en https://github.com/bsotomayor92/Open_Census) para su descarga, contribución y uso. |
[1] Proyecto FONDEF IDeA ID15I10313 “Desarrollo de algoritmos de agrupamiento socio-espacial para develar dinámicas urbanas a partir de datos en tiempo cuasi-real no-convencionales en la planificación, gestión y monitoreo de la ciudad” adjudicado al Laboratorio de Ecoinformática de la Universidad Austral de Chile junto a la Universidad Católica, University College of London, la unidad de Ciudades Inteligentes del Ministerio de Transporte, el Centro I+D de Telefónica e INRIA Chile.
[3] repositorio Github (https://github.com/ecoinformaticaCL/open_census)
[4] disponible en https://www.cepal.org/es/temas/redatam/download-redatam