La experiencia de trabajar con Redatam en estadísticas basadas en Registros Administrativos
Work area(s)
Topic(s)
Teaser
El siguiente articulo corresponde al trabajo que ha venido realizando Miguel Araujo, Subdirector de Análisis y Liberación de Resultados de Registros Administrativos del Instituto Nacional de Estadísticas y Geografía (INEGI) de México quien nos comparte su experiencia a lo largo de los años trabajando con Redatam, específicamente en sus avances migrando bases de datos hacia Redatam, compartiendo experiencia sen su blog de “Aplicaciones para Estadística" y realizando pruebas de procesamiento con las varias versiones de Redatam.
A inicios de la década del nuevo milenio, específicamente en junio del 2003, tuve la fortuna de tomar el curso de “Creación de bases de datos y aplicaciones en formato Redatam” directamente de los creadores y desarrolladores de esta herramienta informática, el equipo de desarrollo de Redatam del CELADE-División de Población de la CEPAL.
La herramienta sin duda catapultó su uso en el Instituto y varias personas de las que fuimos capacitadas empezamos a crear bases de datos Redatam, explotándolas usando el módulo de procesamiento y aquellas aplicaciones XPlan que resultaron tan vistosas y amigables para los usuarios finales.
En el Área de Registros Administrativos generamos algunas bases de datos para las encuestas de salud, cultura e intentos de suicidio y suicidios.
La primera vez que se implementó el uso de Redatam en un proyecto institucional como lo era la entrega de resultados anuales de las estadísticas de museos, espectáculos públicos y museos, fue en los años 2006 y 2007.
Por la evolución tecnológica fue necesario el cambio en los sistemas de recolección (de captura con dispositivos de escritorio hasta aplicaciones web) y debido al poco tiempo que se tuvo para desarrollar aplicaciones con la plataforma Redatam Webserver, los procesos de captura y validación se pudieron realizar en tiempo, pero en el caso de la explotación, no.
Debido a esto y con el apoyo de personal de servicio social y prácticas profesionales (horas de servicio en organizaciones y empresas que piden las instituciones de nivel superior y media superior en México) se logró la entrega de resultados de estas tres estadísticas usando RedatamSP+ Process.
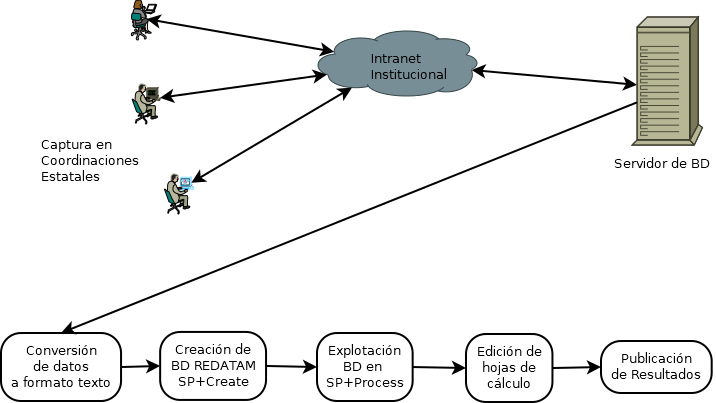
En los años subsecuentes se siguió con los desarrollos y uso de Redatam en el Instituto donde los esfuerzos en el Conteo de Población y Vivienda del 2005 y la conversión a bases de datos Redatam de las estadísticas vitales se siguieron difundiendo en el ecosistema de las estadísticas oficiales en México.
Debido a un cambio de área de un servidor y su equipo, exploramos Redatam alternando las versiones Redatam+SP con Redatam7 en el tema de las encuestas especiales en hogares, nuevamente procesando resultados mediante el módulo Process y editando los resultados en hojas de cálculo que sfueron publicados en la página institucional como parte de los entregables del evento estadístico.
Una de las situaciones críticas que se presentó y que motivó el dejar de lado Redatam, fue la celeridad con el que se debían presentar los resultados en las encuestas y debido a que se requerían descriptores estadísticos como el coeficiente de variación, error estándar y los límites superiores e inferiores y otros, se decidió trabajar con el lenguaje de programación R.
Sin embargo, me dedique a estudiar las potencialidades de Redatam comparándolas con el esquema que se trabaja en la dirección que es el lenguaje R en combinación con Apache Spark, y un motor comercial robusto de base de datos del cual el Instituto tiene licencias del mismo. Así pues, compartí mis experiencias en el blog “Aplicaciones para Estadística” (http://appstatistical.blogspot.com)
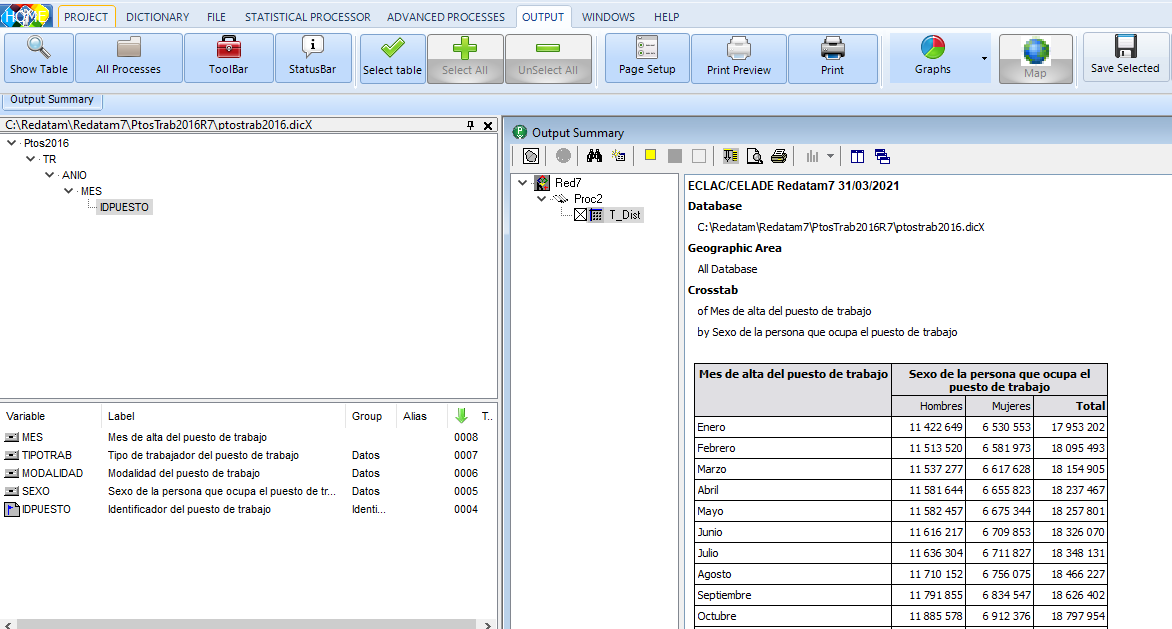
Con el apoyo invaluable del equipo de desarrollo de Redatam estuvimos realizando pruebas con un archivo de datos de 220.816.117 registros que corresponden a la estadística de puestos de trabajo del año 2016 donde se hizo un cruce de sexo contra mes de registro y se cronometraron los tiempos, donde en primera instancia y con las versiones publicadas en el sitio de Redatam había diferencia de segundos entre el proceso utilizando R con Spark y la versión Redatam+SP, siendo la primera quien realizó el mejor tiempo. Luego se repitió el proceso con la versión alfa de RedatamX haciendo el cruce mencionado en un tiempo muchísimo menor. A continuación, comparto los resultados con la tabla comparativa de las herramientas citadas.
- Estadística: Puestos de trabajo 2016.
- Consulta: Cruce de mes de registro del puesto de trabajo contra sexo de la persona que ocupa el puesto de trabajo.
- Número de registros o tuplas: 220, 816,117
- Equipo donde se ejecutaron los procesos:
- Marca y Modelo: DELL Optiplex 9020
- Procesador: Intel CORE i5 a 3.5 GHz
- Memoria RAM: 16GB
Cuadro 1: Cuadro comparativo de velocidades de procesamiento

Fuente: elaboración propia
Los anteriores resultados demuestran que Redatam se está convirtiendo en una poderosa herramienta para el llamado “big compute” por lo tanto, quedamos a la espera de las primeras versiones de la llamada versión RedatamX.
De acuerdo a mi experiencia, los casos de éxito en el Instituto y volviendo a su campo de aplicación, Redatam resuelve el espectro de los censos, encuestas y registros administrativos que las oficinas de estadística en el mundo requieren y los usuarios finales con experiencia nula o media en programación pueden generar resultados utilizando los módulos Process o procesamiento en línea vía Redatam Webserver.
En mi investigación he generado bases de datos desde motores de bases de datos, archivos XBase (DBF), archivos CSV y de texto plano (formato de CSPro) con total éxito y estoy iniciando la creación de aplicaciones web con el módulo Redatam Webserver.
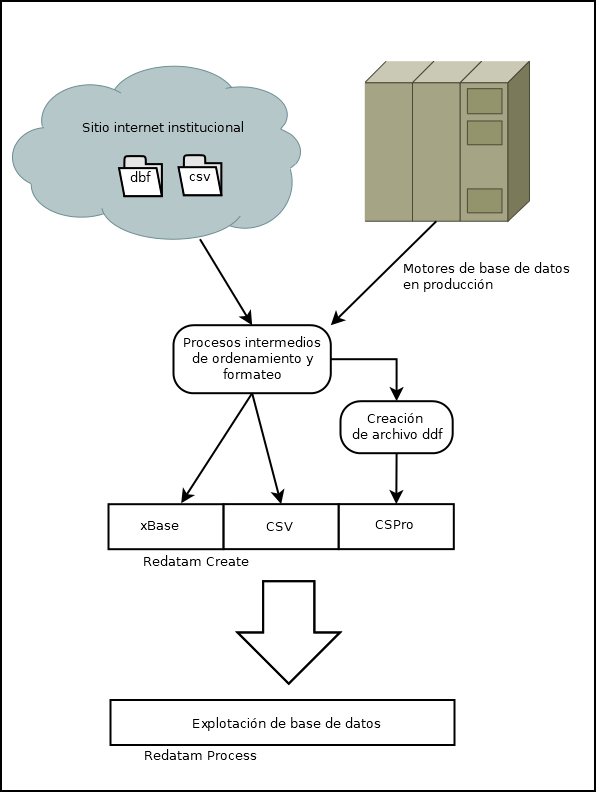
El código de programación para adecuar los archivos como entrada de datos para la base de datos Redatam se ha desarrollado desde el clásico lenguaje manejador de archivos XBase hasta lenguajes más en boga como lo son R y C#. De hecho, cualquier lenguaje de programación que permita la manipulación y creación de archivos de texto es candidato para preparar los archivos de entrada.
Estos esfuerzos deben ayudar a que tengamos nuevamente usuarios finales que exploten las herramientas de análisis y generación de resultados teniendo a disposición con bases de datos que reflejen los hechos estadísticos nacionales, Redatam nuevamente estará en el foco de los integrantes del Sistema Nacional de Información Estadística y Geográfica (SNIEG), investigadores y público en general.
Considero que el motivo más importante de que en nuestro país haya disminuido el uso de la herramienta es la aparente complejidad de la creación de las bases de datos, misma que he abordado en los diferentes artículos de mi blog y que con invertir algo de tiempo, dicha complejidad se solvente sin requerir en demasía de conocimientos técnicos en el campo de las tecnologías de la información o bien reitero que los profesionales en la materia pueden construir los insumos necesarios para la creación de estas bases de datos.
Se observa una creciente demanda en los institutos nacionales de estadística por el uso de herramientas de software libre, donde nuevamente Redatam levanta la mano, ya que permite el procesamiento y análisis de información estadística producida por los INEs a través de la generación de cuadros, indicadores, gráficas, mapas e inclusive formatos de intercambio como lo es SIDRA equiparando a las herramientas comerciales existentes, pero sin los onerosos costos de licenciamiento.
Para concluir hago una reflexión de como los buenos productos permanecen y evolucionan en el tiempo como es el caso de Redatam y reitero mi postura que el Instituto y las unidades de estado que conforman el Sistema Nacional de Información Estadística y Geográfica deben redescubrir y explotar Redatam por todos los beneficios que brinda la herramienta.